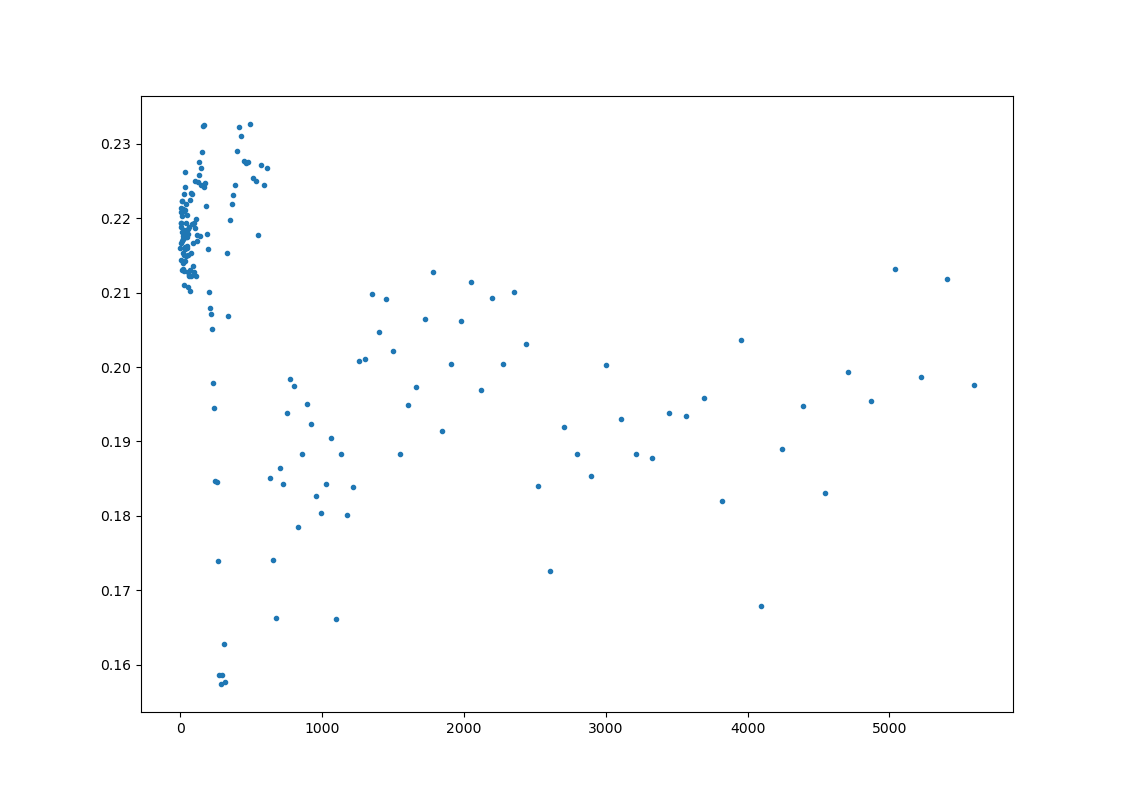
Execution speed varies wildly (47x) between (but not during) runs
Posted: Sun Jan 05, 2020 11:29 pm
Hello,
I'll start with some background info:
driven by curiosity I've been working on a small FPS without external libraries. I've got a first prototype working (video on imgur) with all the linear algebra stuff written in plain lua. Although it's running fine on a desktop PC (~25% of one core) with an extremely simple map I thought it should be possible to improve on this.
So now I'm trying to write a faster linear algebra library using the FFI and metaprogramming.
I'm hoping that using the FFI will help reduce overhead from using tables and that it will help the JIT work it's magic. Also some algorithms (for example the Expanding Polytope Algorithm) use data structures that could be allocated in advance.
Metaprogramming should be useful because the linear algebra library needs a lot of very similar functions, for example adding/subtracting vectors/matrices of different sizes. If I wrote all that by hand it would take ages and it would become very difficult to change anything due to duplication. If I used plain Lua instead but with a style similar to metaprogramming it would cause additional overhead and having the same functions handle different types/numbers of iterations might prevent LuaJIT from compiling those.
The actual issue:
Now that the linear algebra library is working, I made a very simple benchmark that creates a bunch of random vectors, adds some of them together in nonsensical ways and sums the l2-norms of some of the results.
Unfortunately the performance is extremely inconsistent between runs. Sometimes the part the test measures takes ~0.005s or ~0.01s, but most of the time it takes ~0.25s, which is painfully slow. What is even weirder is that the time appears to be constant during each run. The timing doesn't change even if it's running for minutes.
Adding to the weirdness, modifying code that isn't running in the benchmark loop or even code that is completely dead appears to change the likelihood of getting a fast run. For example removing some of the unused metamethods of the vector type led to 7% higher likelihood of fast runs. Ignoring the result of the preprocessor and just loading the vector type from a pre-made file does not change the result. But removing the preprocessor completely and just using it's previous output "disables" the sub-0.25s case completely.
What the program consists of:
While this example is hardly minimal, I wasn't able to remove more and still get high-performing runs.
To be able to run with and without love, the preprocessor uses io.open for loading templates, so it probably won't run as a .love file. Instead unzip the files and start "love ." from inside the folder.
If you're on Linux you can use statistics.py to run the program 100 times. It outputs the total time for every run to stdout as a list.
Probability distributions:
These histograms show the distribution of total runtime (including starting and stopping love) under various conditions. 100 samples each.
Edit: There was a sentence I forgot to finish.
I'll start with some background info:
driven by curiosity I've been working on a small FPS without external libraries. I've got a first prototype working (video on imgur) with all the linear algebra stuff written in plain lua. Although it's running fine on a desktop PC (~25% of one core) with an extremely simple map I thought it should be possible to improve on this.
So now I'm trying to write a faster linear algebra library using the FFI and metaprogramming.
I'm hoping that using the FFI will help reduce overhead from using tables and that it will help the JIT work it's magic. Also some algorithms (for example the Expanding Polytope Algorithm) use data structures that could be allocated in advance.
Metaprogramming should be useful because the linear algebra library needs a lot of very similar functions, for example adding/subtracting vectors/matrices of different sizes. If I wrote all that by hand it would take ages and it would become very difficult to change anything due to duplication. If I used plain Lua instead but with a style similar to metaprogramming it would cause additional overhead and having the same functions handle different types/numbers of iterations might prevent LuaJIT from compiling those.
The actual issue:
Now that the linear algebra library is working, I made a very simple benchmark that creates a bunch of random vectors, adds some of them together in nonsensical ways and sums the l2-norms of some of the results.
Unfortunately the performance is extremely inconsistent between runs. Sometimes the part the test measures takes ~0.005s or ~0.01s, but most of the time it takes ~0.25s, which is painfully slow. What is even weirder is that the time appears to be constant during each run. The timing doesn't change even if it's running for minutes.
Adding to the weirdness, modifying code that isn't running in the benchmark loop or even code that is completely dead appears to change the likelihood of getting a fast run. For example removing some of the unused metamethods of the vector type led to 7% higher likelihood of fast runs. Ignoring the result of the preprocessor and just loading the vector type from a pre-made file does not change the result. But removing the preprocessor completely and just using it's previous output "disables" the sub-0.25s case completely.
What the program consists of:
While this example is hardly minimal, I wasn't able to remove more and still get high-performing runs.
- main.lua Small benchmark
- preprocessor.lua Tiny preprocessor used for processing templates
- la2.lua Linear algebra. Uses preprocessor to lazily create vector metatypes.
- hateful.lua The benchmark but without love (and without precise timing). Is always slow for some reason.
- templates/vec.lua Template for creating vector metatypes.
- templates/vecmeta.lua Template for creating vector metatables.
- test_PrePro_debug.lua Output of the preprocessor for vec4.
- stuff/* Some boring utilities.
To be able to run with and without love, the preprocessor uses io.open for loading templates, so it probably won't run as a .love file. Instead unzip the files and start "love ." from inside the folder.
If you're on Linux you can use statistics.py to run the program 100 times. It outputs the total time for every run to stdout as a list.
Probability distributions:
These histograms show the distribution of total runtime (including starting and stopping love) under various conditions. 100 samples each.
- The preprocessor is not loaded at all. Instead previous output of the preprocessor is loaded via require.
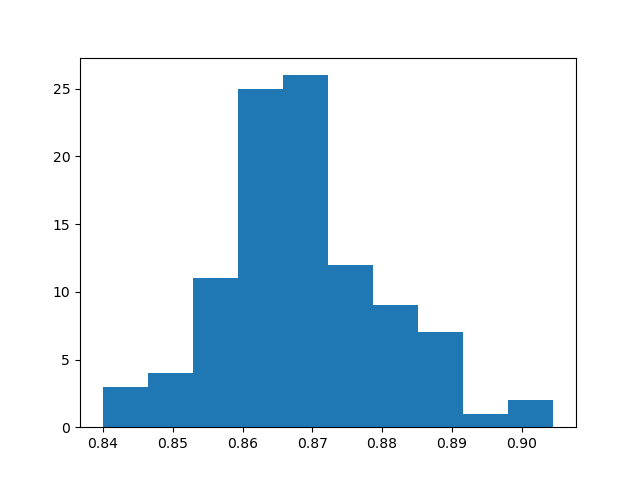
- The preprocessor is enabled but it's output is discarded. Instead previous output of the preprocessor is loaded via require. The preprocessor does not directly interact with the code in the benchmark at all.
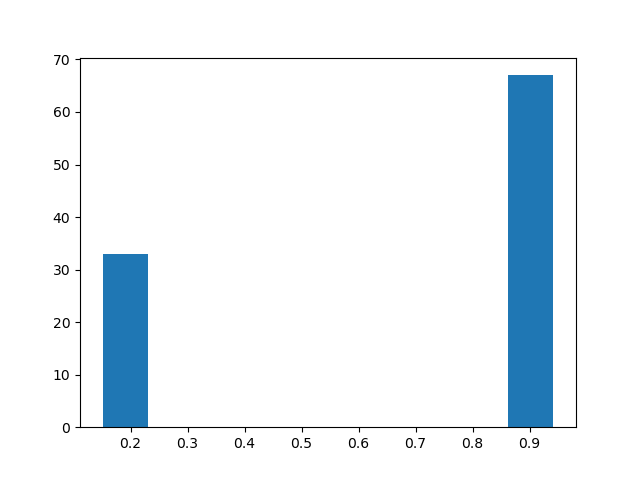
- More results on imgur
- Why is performance varying this wildly? Why does changing seemingly unrelated things completely change the distribution?
- What can be done to get this working reliably? Are there possible workarounds?
- What tools are there to investigate?
- Are there any other things I could be doing better?
- Are there potential problems with using union?
- Why is performance consistently poor when I run it directly with LuaJIT instead of using Löve?
- Are there other places on the internet more suited to this question?
Edit: There was a sentence I forgot to finish.